WarpRF: Multi-View Consistency for Training-Free Uncertainty Quantification and Applications in Radiance Fields
Sadra Safadoust, Fabio Tosi, Fatma Güney, and Matteo Poggi
In Winter Conference on Applications of Computer Vision (WACV), 2026
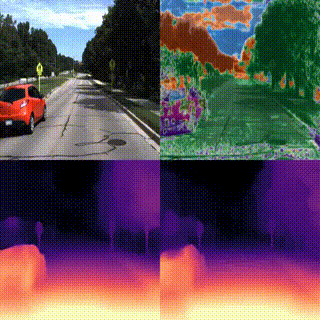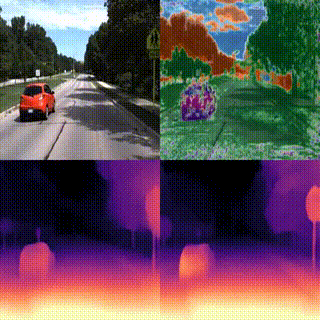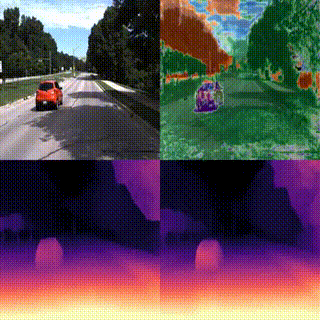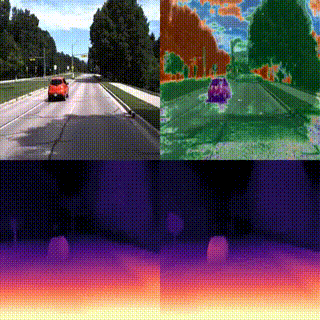
We introduce WarpRF, a training-free general-purpose framework for quantifying the uncertainty of radiance fields. Built upon the assumption that photometric and geometric consistency should hold among images rendered by an accurate model, WarpRF quantifies its underlying uncertainty from an unseen point of view by leveraging backward warping across viewpoints, projecting reliable renderings to the unseen viewpoint and measuring the consistency with images rendered there. WarpRF is simple and inexpensive, does not require any training, and can be applied to any radiance field implementation for free. WarpRF excels at both uncertainty quantification and downstream tasks, e.g., active view selection and active mapping, outperforming any existing method tailored to specific frameworks.